- Ingres for (Oracle) Dummies slideshow
- neo4j, a Java implementation of a graph database
A graph is a collection nodes (things) and edges (relationships) that connect pairs of nodes. Slap properties (key-value pairs) on nodes and relationships and you have a surprisingly powerful way to represent most anything you can think of. In a graph database "relationships are first-class citizens. They connect two nodes and both nodes and relationships can hold an arbitrary amount of key-value pairs. So you can look at a graph database as a key-value store, with full support for relationships."
A graph looks something like:
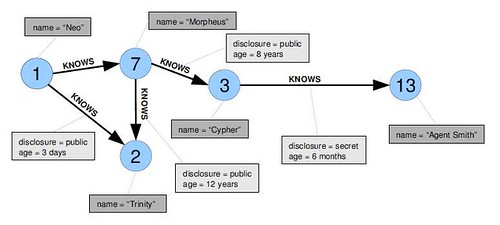
For more lovely examples take a look at the Graph Image Gallery.
Here's a good summary by Emil Eifrem, founder of the Neo4j, making the case for why graph databases rule:
So relational database can't handle complex relationships. Graph systems are opaque, unmaintainable, and inflexible. OO databases loose flexibility by combining logic and data. Key-value stores require the programmer to maintain all relationships.
Most applications today handle data that is deeply associative, i.e. structured as graphs (networks). The most obvious example of this is social networking sites, but even tagging systems, content management systems and wikis deal with inherently hierarchical or graph-shaped data.This turns out to be a problem because it’s difficult to deal with recursive data structures in traditional relational databases. In essence, each traversal along a link in a graph is a join, and joins are known to be very expensive. Furthermore, with user-driven content, it is difficult to pre-conceive the exact schema of the data that will be handled. Unfortunately, the relational model requires upfront schemas and makes it difficult to fit this more dynamic and ad-hoc data.
A graph database uses nodes, relationships between nodes and key-value properties instead of tables to represent information. This model is typically substantially faster for associative data sets and uses a schema-less, bottoms-up model that is ideal for capturing ad-hoc and rapidly changing data.
- From a blogger: One of the arguments that the pro RDBMS folks make for why there is no need for the graph database model is that you can do everything that can be expressed in a graph database in a relational database. And there is some truth to this.
But there are two problems with this argument. The first is that this is only true in theory. It is not possible to build a graph database of scale using pure SQL – at least with the SQL tools that we currently have to choose from.
One reason for the scale problem is the only way to do it is to do what are called self-joins. This is when you join a table to itself. Conceptually seem just fine. But the problem is that it is impossible for the database engine to do anything other than brute force un-optimized traversals of the graph when confronted with a chain of self-joins. In other words, using this technique will not yield a useful database that is query-able at any kind of scale. Handling certain aspects of providing a graph database model requires some very specific and different kind of thinking and optimizations from those that go into designing an SQL database.
Another problem is that one giant table using self joins for traversal means a huge write bottleneck. Yes, you can avoid that with sharding depending on your design, but it is definitely not part of the SQL model, and so you can’t say SQL is helping you here.
The second and I believe more important argument against implementing a graph data model using SQL is that even if SQL could do a good job of representing a graph model, building your graph system in SQL is not a very good abstraction. The truth is that most of the kinds of things we want to do in app development look more like graph than relational structures. Graphs are elemental to computer science because most interesting algorithms and in fact real world data models can be very naturally thought of as a graphs. Graph theory is (if things are as they were when I was in school) the first thing you learn when you begin studying computer science, and there is very good reason for this. The fact that Facebook was able to anchor the idea of what they were building as a “social graph” is an incredible testament to the innately natural characteristics of the graph concept.
So if you are representing a graph, you really want an API that reflects the unique and useful characteristics of a graph. In other words, you want an abstraction that reflects how you really think about the data and not some jury-rigged representational model continuously intruding itself into your thought process. And so, having a data store that allows us to express our data in a way that is much more similar to how we actually think is enormously helpful.
And such is the case with attempting to implement a graph database using SQL. You can do it, but it is unlikely to work very well, and because you don’t have the benefit of the abstraction, it actually adds to the complexity of the design instead of simplifying it.
The bottom line is that graphs are a better representational model when the structure of your system will change frequently. Relational is a better model when the structure will be static. Today, I think most of us are not building applications that are ideally structurally static.
Because most applications today have a much more dynamic nature, graphs are, for most people, under most circumstances, a far better abstraction. And to me, there is little in this world more powerful and satisfying than a great abstraction.
- an extension to Domain-Driven Design i.e. Composite Oriented Programming implemented in Java
Decoupling is Virtue
Decoupling is more important than developers in general think. If you could have every OOP class decoupled from all other classes, it is easy to re-use that class. But when that class references another class and the chain never ends, your chances of re-use diminishes quickly.
Object Oriented Programming is suffering a lot from this, and many mechanisms have been introduced over time to counter this problem. But in reality, the best we can manage is subsystems of functionality, which client code can re-use. And these subsystems tend to be infrastructure related, since domain models are less prone to be similar enough from one project to the next, and since OOP in reality constrains the the re-use of individual domain classes, we need to re-do the domain model from scratch ever time.Business Rules matters more
Smart developers often think that low-level, infrastructure and framework code is more important and more cool to work with, than the simple domain model. But in reality, it is the Domain Model that reflects the actual need and pays the bills. Infrastructure is just a necessary evil to get things done.
If most developers could focus on the Business Rules and Domain Model, and not having to worry about any infrastructure issues, such as persistence, transactions, security or the framework housing it all, the productivity would surge. Eric Evans has written an excellent book about Domain Driven Design, where he goes through the real process that makes the money for companies. However, it is very hard to follow that book, since one is constantly caught up in constraints irrelevant to the domain model, introduced by the underlying framework, from the so called smart developers.
Qi4j is trying to address the flaws of OOP and introduce Composite Oriented Programming to the world, without introducing new programming languages, or awkward constructs. Heck, we don't even use any XML.
Qi4j is not a framework. It is a new way to write code.
Thursday, October 29, 2009
A few topics of interest to me, today

Subscribe to:
Post Comments (Atom)
No comments:
Post a Comment